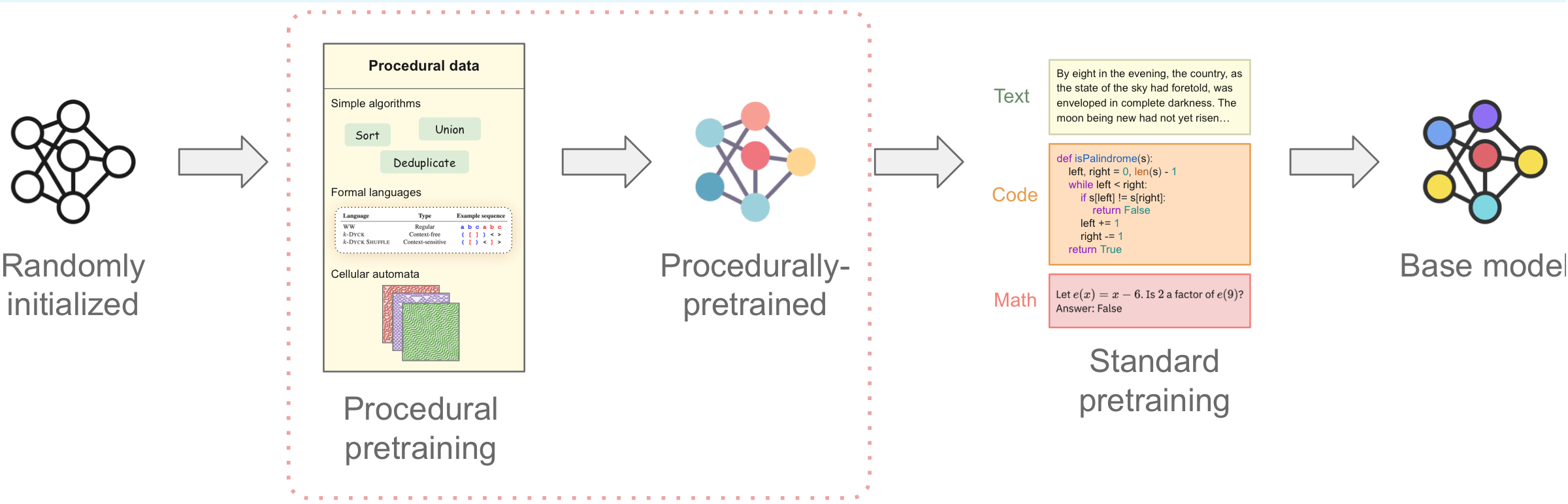
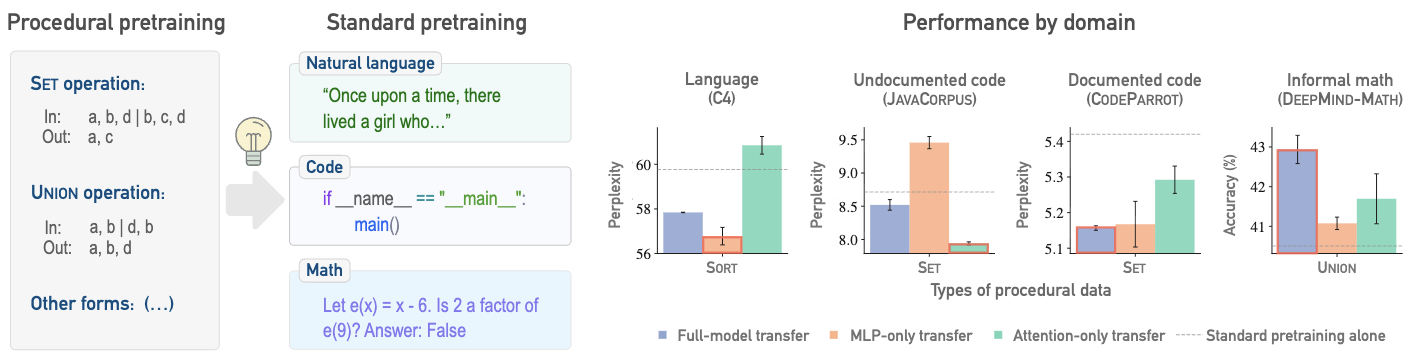
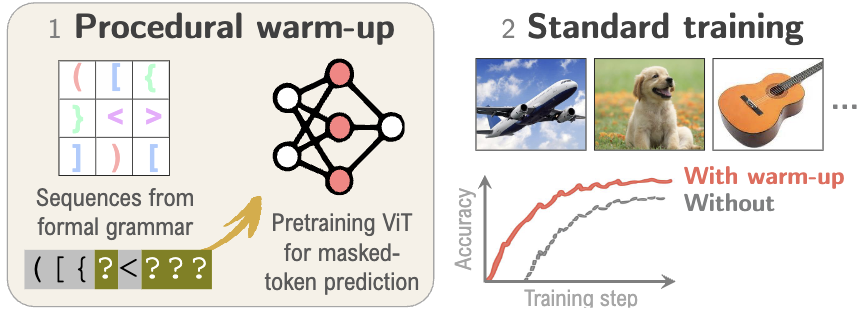
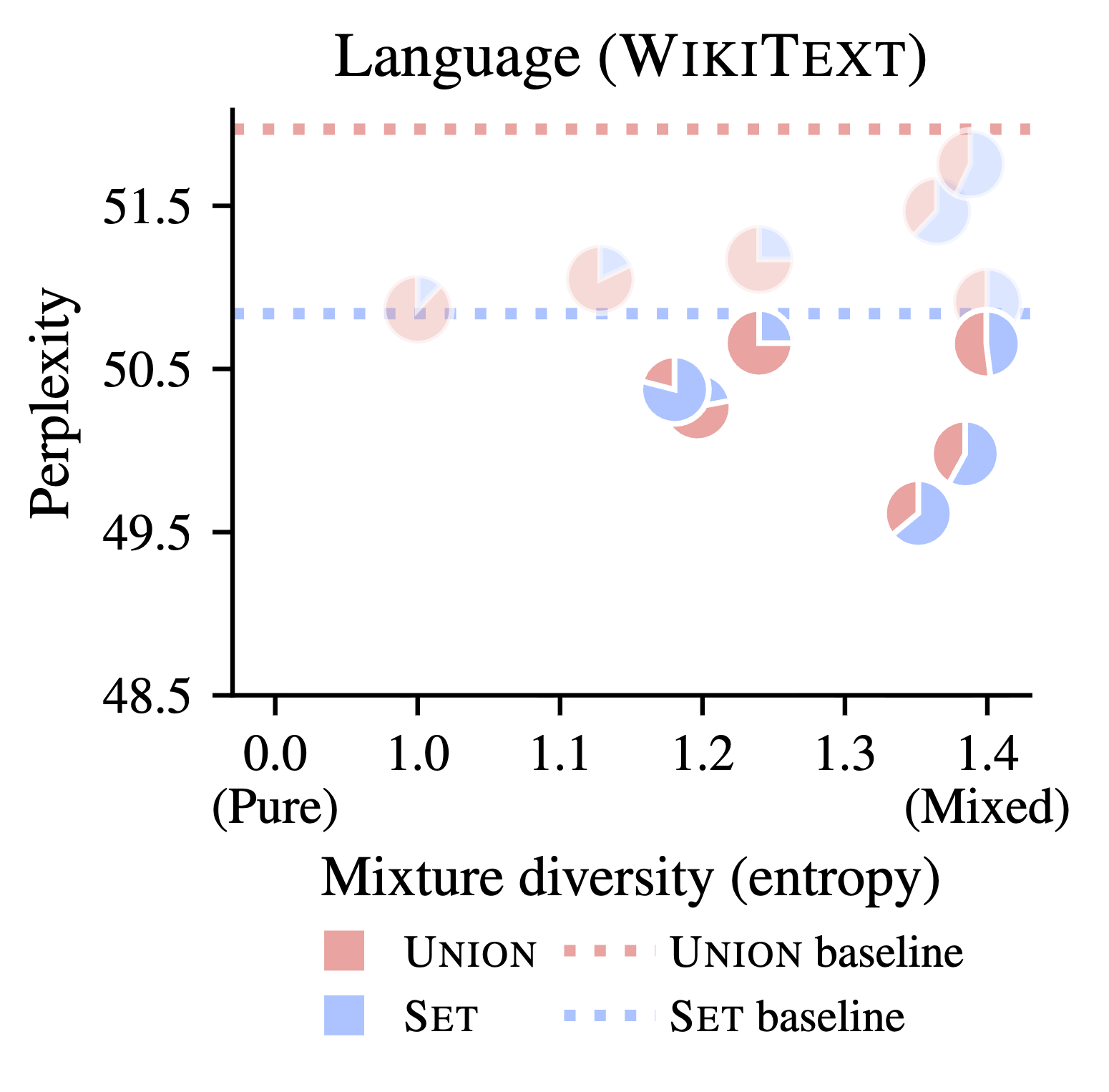
Current pretraining paradigms expose models directly to web-scale data, text, code, images, expecting them to simultaneously learn both world knowledge and reasoning mechanisms. We show that a brief initial exposure to procedural data, sequences generated by formal grammars and simple algorithms, completely devoid of semantic content, can dramatically improve subsequent training.
Much like how infants learn simple logic and pattern matching before higher reasoning, procedural pretraining builds general computational mechanisms into transformers before they encounter real-world data. This scaffolding accelerates convergence, improves final performance, and reduces data requirements across diverse domains.
We demonstrate these benefits for large language models (on natural language, code, and mathematics) and for vision transformers (on image classification), showing that procedural data injects useful modality-agnostic priors that complement standard training.